客服热线:0755-28448218 189-26549444
“轴承寿命预测”为什么不准? |
| 来源:哈尔滨轴承 发布时间:2024-12-09 16:31:01 |
轴承寿命预测是很多轴承使用者关注的话题,同时也是各种轴承技术人员、研究者都十分关注的热门方向。关于轴承寿命预测的各种论文、研究成果林林总总。单独从文献角度看,貌似轴承寿命预测问题已经被很好的解决了。可是另一方面,在轴承实际应用领域,几乎没有一个轴承预测的方法可以准确预知轴承寿命(或者是轴承啥时候会坏)。这是怎么回事?我们今天说一说轴承寿命预测的一些问题。
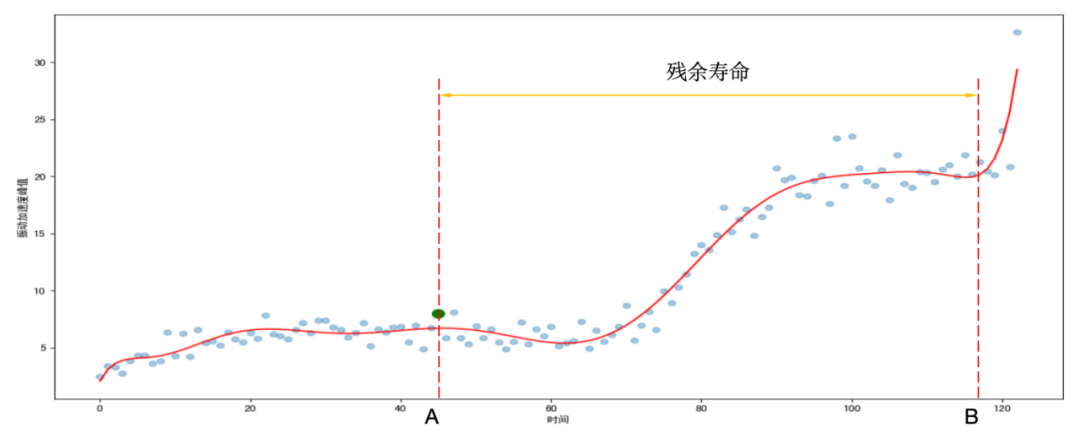
目前对轴承寿命预测的主要方法包括从理论上进行计算以及基于轴承运行数据的模型算法计算。 轴承寿命的理论计算轴承寿命的理论计算是工程师经常使用的方法,不过,大家通常使用的L10计算是轴承的疲劳寿命计算(可靠性为90%)。本文不展开讨论这个计算方法的本身。但是从这个计算方法不难知道,L10计算仅仅考虑轴承本身的疲劳寿命,并且在计算中,通过当量负荷的方式,将外界的负荷折算成一个恒定的径向负荷。这两个处理方式,一方面简化了计算,另一方面也使计算结果出现了偏差。 首先,轴承的实际运行寿命不仅仅是轴承的疲劳寿命。很多轴承的损伤和提早失效不属于疲劳范畴(例如,磨损,腐蚀,电腐蚀等等),因此这个疲劳寿命计算的结果和实际轴承寿命本身存在较大的对象差异。另一方面,这个计算仅仅考虑钢球和滚道,没有考虑保持架、密封结构等相关零部件。因此,总体而言,这个计算很难严格对应于轴承的真实使用寿命。 另一方面,轴承的实际承受负荷与计算时候的等效方式不同。轴承经常工作与动态负荷,变动温度等工况下,而非计算中的等效的那样,工作与一个恒定负荷长时间稳定运行的情况,有时候轴承还会工作与变动转速的情况。当然,现在有一些修正寿命计算方法,使用轴承的载荷谱对轴承的载荷谱进行等效,这样的计算很大程度接近了轴承的实际工作状态,但仍人存在一些不可控因素。修正寿命计算中,也考虑的润滑的影响,和轴承材质的影响,然而这些修正仅仅使寿命计算与真实寿命有所接近,但也远非真实寿命的预测计算。 通过上面讨论,我们知道基本的轴承寿命计算存在很多计算条件前提和边界,因此他不适用于轴承的寿命预测。更合适用于轴承的选型校核(这一点在其他文章中有详细介绍)。 基于数据的轴承寿命预测随着大数据分析技术的发展,机器学习等先进的人工智能方法被应用于越来越多的领域,包括轴承寿命预测。可以轻易的找到很多论文和研究声称对轴承寿命进行了良好的计算。然而实际工程应用中,却鲜有成绩。这是为什么呢? 我们先了解目前数据分析方法的思路,然后讨论为什么不准。 首先,机器学习方法是基于数据建立模型。如果要对轴承进行寿命预测,就必须拥有一定量的轴承全生命周期数据。然后使用大量轴承全生命周期的数据建立起轴承运行表现与时间关系的模型。当一个轴承实际运行的时候,将这个轴承当前的运行状态输入模型,从而得知该轴承在轴承全生命周期中所处位置,从而预测轴承还能工作多久,也就是完成了轴承的寿命预测,如图所示:
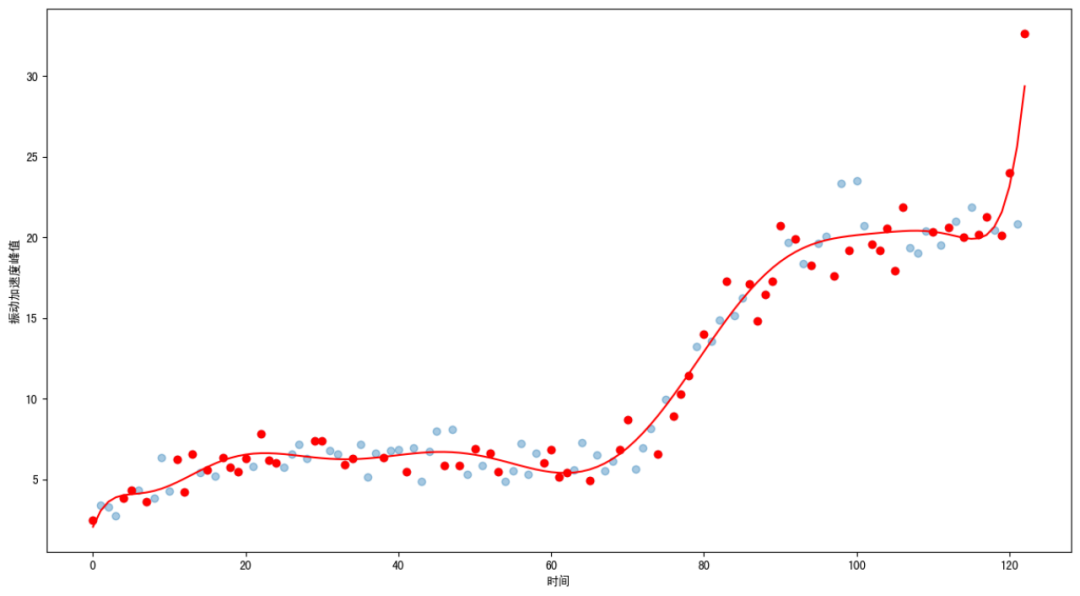
图中,通过轴承全生命周期数据,建立了轴承全生命周期的振动加速度峰值曲线。在进行轴承寿命预测的时候,首先获取当前轴承的状态数据——A点。曲线中,B点为轴承的实效点,因此A B间的时间间隔即为轴承的残余寿命,由此完成了轴承的寿命预测计算。 以上思路总体上是合理的,但是在实际应用中存在很多无法实现的地方。 首先,轴承的全量数据集,也就是轴承的全生命周期数据。对于设备使用者而言,几乎很难得到轴承全生命周期数据。举个例子,你买一台电扇,你怎么可能用坏好几遍来建立模型来计算下一个轴承的寿命呢?当然,对于设备的生产厂而言,是具备这种收集数据集的可能的,但是他们有两方面困难,第一,不是所有客户都会把运行数据给制造厂家;第二,每一个用户的使用条件、工况时不同的,因此其全生命周期曲线也是不同的。设备厂家不可能为每一个设备使用工况建立模型。因此,在很多设备使用者的具体应用中,几乎都会因为缺乏数据而无法建立模型。 这样的话,只能根据部分数据建立模型。 使用机器学习建立模型基本方法是,首先将数据集划分成训练集和测试集。训练集用来训练模型,测试集用来对模型进行评估。在这个过程中,不同的取样方式带来不同的结果。 很多模型中,经常采用随机取样的方式,就是从全量数据集合中,随机抽取一定比例的数据作为训练集,另一些数据作为验证集。如下图所示:
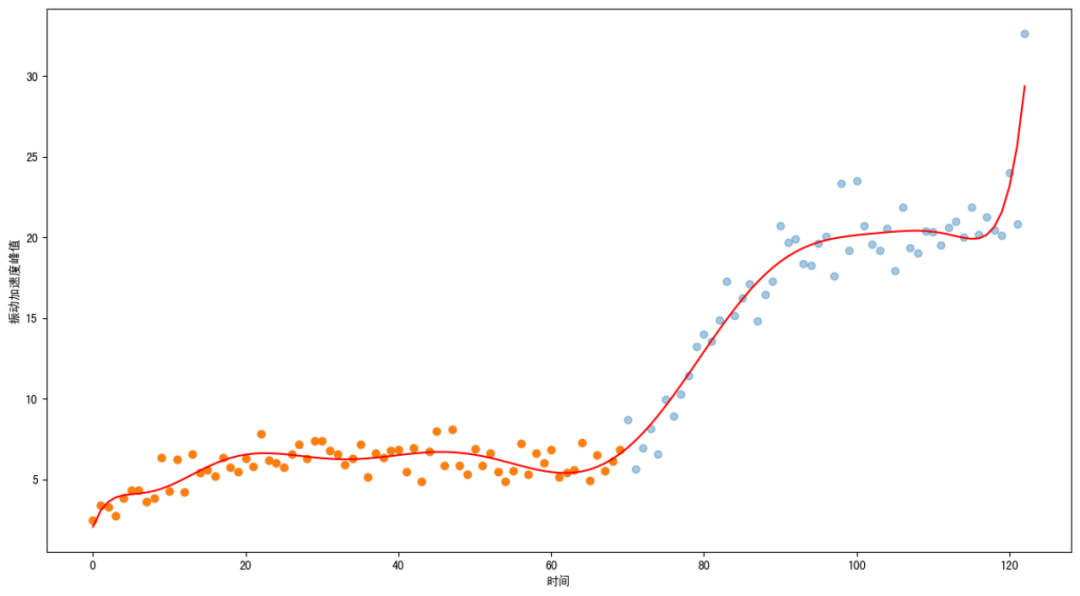
图中随机抽取了50%的数据建立模型(事实上,真实建模应该抽取70%-80%)。可以看到模型曲线较好的模拟了轴承的全生命周期状态。请注意,这里存在一个前提,是基于全量数据建立模型。模型虽然貌似准确,但是如果没有全量数据,这个模型建立不起来。很多文章中对这一点一带而过,带来很多误解。事实上,轴承的寿命预测是对轴承状态的时域分析,因此训练集和验证集不应该随机选择,应该按照时间前后划分的方法进行选择。我们看下面的图:
图中,橘黄色部分为拥有的数据,通过这个数据建立模型,可以得到如下模型结果:
图中,淡蓝色数据是未来数据,应该是未知的。当模型做出了三种预测的时候,在当前数据(红色)中,看到模型效果都很接近,但是无法知道这个模型后续的预测曲线哪一个是准的。换言之,机器学习学习的是现有数据的特征,因此都是基于现有特征对未来可能出现的数据进行预测,也就是说这个模型现有数据特征按照现有趋势发展下去重复出现特征的模型。模型无法对未知情形进行计算。(当然,对于很短的未来,可以进行机选,不过从图中读者不难发现,短期未来的数据不论用什么模型,其实差异应该不大。) 综上,我们似乎得到了一个悲观的结论,就是不论用什么方法(至少是上面提到的两种方法),对未来进行算命都有很大的不确定性。通常运用工具只能尽可能逼近,逼近多少?对不起,不知道?这其实是目前寿命预测在应用上无法落地的根本原因,因此,不需要对“寿命预测”抱有太多不切合实际的期待。
上一篇:没有了!
|


 关注官方微信
关注官方微信